Spanner(スパナ)は、Googleで開発され、利用されている分散データベースである。2012年に設計が論文として公開された。2017年からはGoogle Cloud Platform上で提供が始まり、一般ユーザでも利用できるようになった。
概要
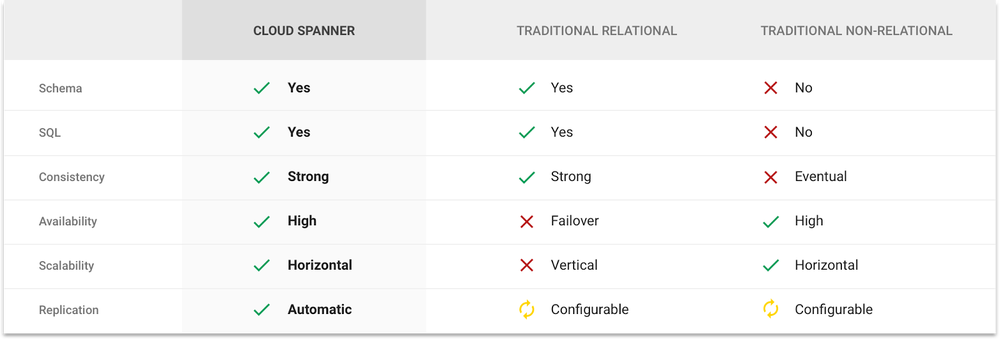
関係データベース管理システム(RDBMS)の構造と非関係データベース(NoSQL)のスケーラビリティを兼ね備えるとされる。
Googleは、Spanner以前にもスケーラブルな分散型データベースであるBigTable(NoSQLデータベース)を社内で利用していた。BigTableは多くのプロジェクトで活用されてきた一方で、従来のスキーマ型のRDBMSのようにデータの一貫性が欲しいという不満も受けていた。この問題を解決するために、Spannerが開発された。
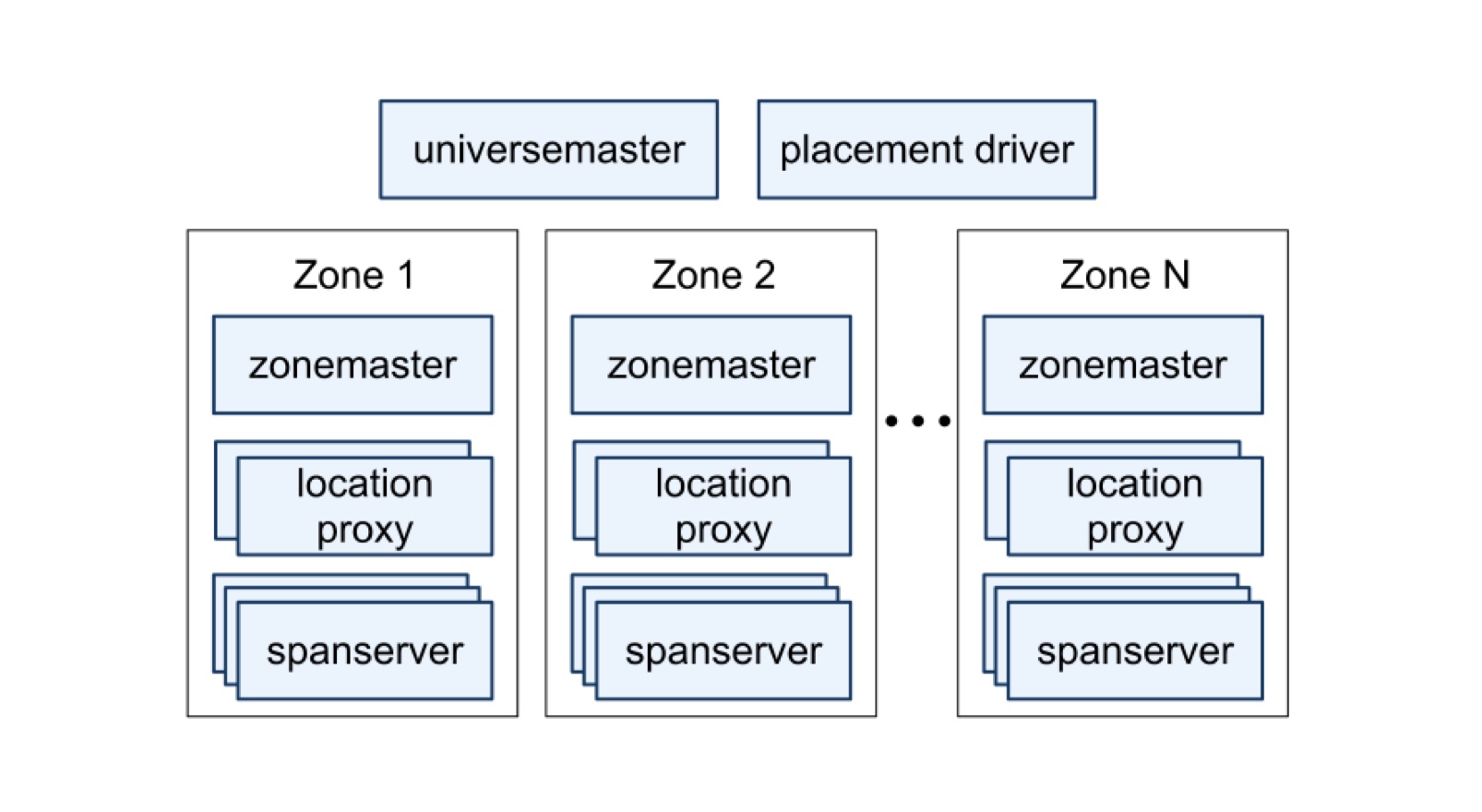
何百ものデータセンターに渡る100万台規模のサーバに分散、スケールするように設計されている。
また、SQL文を利用してデータの更新や集計などが可能である。
後述の通り、タイムスタンプを利用してデータの一貫性を保証する特徴がある。これにより、データベースへの処理が行われている最中であっても、一貫したデータの読み書きが行えるだけでなく、一貫したバックアップ、MapReduce処理が可能であるとされる。
技術詳細
上記の通り、Spanner ではデータの一貫性を担保する必要があった。これを実現するために、BigTableとは異なり、Spanner ではタイムスタンプが必ずデータに付与される。このデータ構造はtabletと呼ばれ以下のようなマッピングを持つ:
(key:string, timestamp:int64) -> string
これらデータはGoogle File Systemの後継であるColossus上に全て保存される。
上記のようにタイムスタンプを用いることで、全てのトランザクション処理のコミットがどの順番で行われたかを管理でき、これによって、一貫性を保証できる(詳細はMultiVersion Concurrency Controlを参照)。
ここで重要となるのは、タイムスタンプを一貫した時刻基準を用いて押し、処理した順番を誤って前後させないことである。しかしながら、Spannerのようにデータが複数のサーバに分散される場合は実現が難しい。全てのサーバを常に、かつ厳密に同時刻に保つことは困難なためである。
これを解決するために、Spannerでは、TrueTime APIを利用して、現在の絶対時刻をある幅TTinterval: [earliest, latest]を持たせて取得する。これは、現在の絶対時刻が、earliest以上、latest以下であることを保証する。すなわち、Spanner のサーバ群の中で最も早い/遅い時間は、それぞれearliest/latestであり、他の全てのサーバはこの範囲内に収まるということである。このように、時刻ずれのワーストケースが分かっているため、処理の順序関係に不整合がでないようにデータベースの読み書きを制御する事が可能となり、データの一貫性が保たれる。
時刻のずれ量が大きくなるほど、処理をコミットするまでの待ち時間が大きくなり、性能が劣化する。このため、SpannerではGPSや原子時計を利用した正確な時刻基準をマスター・サーバに利用して、できる限りスレーブ・サーバ間のずれを少なくするようにしている。
脚注
関連項目
- トランザクション処理
- ACID (コンピュータ科学)
- NoSQL
- BigTable
- Google File System
- Network Time Protocol
外部リンク
- Spanner: Google's Globally-Distributed Database
- CLOUD SPANNER